Enterprise Search Summit 2006 Review
I just returned from attending the 2006 Enterprise Search Summit in NYC and must say that it was encouraging to see the tremendous amount of interest and growth in the enterprise search market. There were about 1000 attendees, which was a three fold increase from last year. All of the search vendors were there as well as good attendance by enterprise customers seeking search solutions. What follows are some of my observations, views, and experiences at the conference.
Keynote Speaker:
Peter Morville, President of Semantic Studios, gave an interesting speech about “Ambient Findability” which coincidentally is the title of his new book. Schooled as a librarian, Peter gave a more holistic view of search, defining it beyond just the search and retrieval of text documents, but the ability to find anyone or anything from anywhere at anytime. He cited Google Maps, PodZinger, and even Cisco’s wireless location appliance as examples of alternative forms of enterprise search. He riled at Google’s suggestion that there is just one simple to use interface (think of “Onebox”) with its persistent “flat” list of results. Peter feels that its more about navigation and way finding through a mashup of digital content in all shapes and forms. Peter also reminded us of the rapid adoption of mobile devices such as cell phones, Blackberries and iPods which are morphing into multi-informational devices (e.g., cell phones to find restaurants, iPods to watch video, etc..). Overall, I thought Peter’s talk was good, stimulating me to think outside of the conventional enterprise search box (probably worth reading his book).Who’s Hot and Who’s Not
At the end of the conference Steve Arnold, an independent search analyst, gave his views of Who’s Hot in the enterprise search industry. First, he identified three major trends in the industry. They are:- Search Platforms – Steve identified IBM, Oracle, Microsoft, FAST, and Autonomy as vendors providing enterprise search platforms. His message was that if you are in the process of selecting an enterprise search engine and you choose products from anyone of these vendors then you are locked in which makes it extremely difficult and costly to switch later.
- Appliances and APIs – While most in the audience could only name Google as providing a search appliance, Steve said that most of the vendors he talked to had plans or were on the verge of releasing their own search appliances. Steve also said that although “appliance” implies dead easy to use he wasn’t so sure it could be achieved due to the complexity of enterprise content. As for APIs Steve said that everyone has one but what to look for are APIs that are SOA (Web Services) or REST based.
- Specialization - Steve also felt that more and more vendors are turning towards very domain specific search solutions. He cited Oracle and Convera as leaders in specialization. At the top of Steve’s list of who was hot was Vivisimo. He felt that Vivisimo, overall, had the most robust set of functionality. Besides Vivisimo’s well-known result set clustering and other capabilities, Steve noted their move towards federation. Steve felt that there is no one search engine for the enterprise, primarily because of embedded search and that Vivisimo can be used to help solve this multi-search system problem. Other vendors he highly recommended to look at were Endeca, Coveo, and MondoSoft. Coveo and MondoSoft are partnered with Microsoft and have plug-ins for the Sharepoint server.
Conference Sessions
Besides Peter Morville’s taunt to think outside of the box, I didn’t see or hear anything dramatically new in the enterprise search space. Taxonomies, multi-faceted search, metadata tagging, and search engine optimization were reoccurring themes throughout the conference.User Interface Design
I was hoping to see some dramatic breakthroughs in user interface design but didn’t. Several speakers dismissed the use of fancy graphics (e.g., 3D interactive topic cluster maps) used for navigation. These they felt were non-intuitive, too abstract and viewed as eye candy for the programmer but useless for the end user. Almost all user interfaces I saw had some form of
multi-faceted search to aid in the navigation of results. I came to realize that this was essential to the user search experience. Rather than rely on the relevance algorithm alone to get the right answer at the top of the list it is better to add alternative ways to find the right answer with just one (or more) clicks. This is different from forcing the user to augment their query with new or additional terms (both thought and time consuming). Note that Google has not embraced MF search and still advocates the “flat” result set. This is probably because they are constrained by the type and amount of metadata returned by the web.
Google’s big play in the enterprise search market is the introduction of the Google OneBox. Google offers an API that lets a developer connect search queries to an external data system.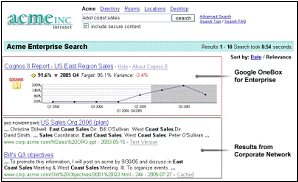 Queries matching a developer defined pattern are passed on to external system, and results are displayed at the top of the search results. Google already provides connectors to Oracle, Cognos, SAS, Cisco and SalesForce.com with more to come. The strategy is to use the Google search box not only as the single point of access to all web content but to your enterprise applications as well. This is quite a potential threat and has many search vendors nervous. For the non-search vendors, it is viewed as a way to expose their often complex functionality through an already accepted dead simple interface resulting in more awareness of their products.
Queries matching a developer defined pattern are passed on to external system, and results are displayed at the top of the search results. Google already provides connectors to Oracle, Cognos, SAS, Cisco and SalesForce.com with more to come. The strategy is to use the Google search box not only as the single point of access to all web content but to your enterprise applications as well. This is quite a potential threat and has many search vendors nervous. For the non-search vendors, it is viewed as a way to expose their often complex functionality through an already accepted dead simple interface resulting in more awareness of their products.
Actionable results
We have all heard of the requirement to highlight search terms in the document after it is clicked on for display and to position the user to the place in the document where the search terms are highlighted (useful for very large documents). But Inxight took this concept several steps forward. They provide a search extender to the Google Appliance and Desktop search that extracts people’s names, companies and 25 other entities from the result document and provides the facets on the left as navigation into the document itself. The document is first clicked on and displayed from the Google view cache (search terms are already highlighted). Then by clicking on any of the facets on the left (say people), the document is positioned to the page that contains the highlighted facet.
Best Bets
Surprisingly a lot of time was devoted to the discussion of “Best Bets” or “QuickLinks” as we know them. The message was that the overall goal of the search engine is to help find what the user is looking for and that no matter how good the search engine is it is not going to always produce the most relevant results. They encouraged the search administrators to closely examine their top queries and manually provide the QuickLinks for these results to dramatically increase customer satisfaction. While admitting that this is a kind of crutch they felt it was necessary to keep customer sat high while you figure out why the search engine was not placing the right results at the top. They also pointed out that the right answer should always be number one, not three, and that Best Bets is one way to ensure that it’s at the top. In either case, what I got out of this is that our search products should have a robust search quality reporting system that produces the information needed to perform this type of analysis. At a minimum there needs to be the following reports:
- Top queries (by query term and submitted frequency)
- No Results
- Results with no click through
- Next page of results
Social Bookmarking and Folksonomies
A poll of the audience showed that the majority were working on content taxonomies in one form or another as a way of augmenting their search solutions. Several speakers addressed the challenges in taxonomy generation which is heavily reliant on document tagging with metadata. Automatic metadata generation (e.g., clustering) is still in its infancy and not heavily used so most companies either rely on professional or author creation of metadata. Using professionals can be expensive especially in an enterprise with vast amounts of information. Author generated metadata can be inadequate, inaccurate, or outright deceptive, so several speakers talked about leveraging the user community as a way to help solve the problem.
The idea is to let your users organize the content for their own use as they see fit - much the way we bookmark web pages with our own terms. The key is to then make these tags available to the rest of the user community. The result is an unpredictable but highly accurate folksonomy of documents. This initial tagging can then be used as the basis for building the ultimate taxonomy. Note that taxonomy generally implies a hierarchy where a folksonomy is one level deep (a flat list of words associated with the document). There were many web based folksonomies cited - Del.icio.us, Flickr and even IBM’s DogEar to name a few. But they indicated that the model is working its way into the enterprise. More vendors are providing the tools to allow for the tagging of search results and sever based components to share those tags and/or assist in the overall taxonomy generation process.
Conference Grade (B+)
Overall I found the conference to be very informative and worth while to participate in the future. Don’t hesitate to contact me if you have any questions or would like to discuss a topic in more detail.Click here to read more...
posted by Todd Leyba at 8:29 AM
|
0 comments
![]()
![]()




