Are Sitemaps the Answer to Crawling?
They say you must crawl before you can walk so it must follow that you crawl before you can search. That certainly has been the case up until now.
Crawling refers to the process of extracting content from the web. Given an initial URL a crawler (program) will fetch the web page, scan it and extract all of its text for indexing. As the crawler is doing this it keeps track of any other URLs (links) that it encounters in the web page. Once the crawler has finished with the page it then fetches in succession the web page associated with each URL it found in the current page and repeats the process. This process of following links resembles that of a spider traversing the pathways in its web, hence the term crawling. Sounds simple enough, but there are many drawbacks to this brute force approach.
First the crawlers must be careful not to get caught in an infinite loop which is what would happen if two web pages pointed to each other. This means that the crawler needs to keep track of each and every URL that it visits - an arduous task when trying to crawl the entire web. Note that Google currently claims over 10 billion web pages indexed which is still just a fraction of the total content on the web.
The other problem is how a crawler is to detect change. Each web page is supposed to contain a “last modified” date but this is rarely updated by the web sites and shouldn’t be trusted. The only sure way to detect change is for the crawler to revisit the page and compare it to its previous state when last visited. Hmmm…so does that now mean that the crawler needs to keep a copy of the original web page so that it can be compared later? Some clever crawlers actually keep a unique 32 byte MD5 key generated from the content and compares it to the MD5 key generated from the new content. If the keys are different then there was a change somewhere in the page. While 32 bytes is considerably less than the page itself we are still talking about more storage. And crawlers typically keep much more information about a web page then mentioned here.
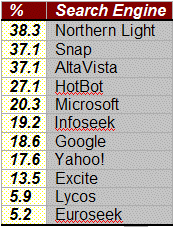
Another problem is the number (or coverage) of web pages visited by the crawlers. Naively there are those who think they are searching the entire web when using a popular web search engine when in fact it is only a fraction of the web. Steve Lawrence and C. Lee Giles of NEC Research Institute used 1,050 real queries from NEC researchers in order to test web engine coverage. Of the 42 percent of the web covered by the search engines, a breakdown of their coverage is shown in the table to the right. Lawrence and Giles have compared these percentages with studies done in the past and have concluded that the web search engines are not keeping pace with the growth of the Web.
There are many factors that can lead to this. Just the sheer processing power alone required to crawl the 16 million web servers in existence today can get in the way. But it should also be obvious that what gets crawled depends on its placement in the web of interconnected links and where the crawler starts. If I have created a new web site it is safe to assume that no one in the web has “links” pointing to my page yet. Hence, my web site is invisible to the crawlers. There are ways around this problem. You can enter your URLs into several of the popular web directories, encourage other sites to link to your pages, or use the manual “add URL” feature offered by most of the public search engines. But this process is somewhat hit or miss and relies on the hope that the crawlers will eventually visit your site. The Lawrence and Giles study mentioned above found that search engines take months to find and index a new page. The average median age of “new” pages was 57 days.
A promising new standard proposed by Google offers to remedy these problems. Referred to as “Sitemaps” the proposal is for webmasters to inform search engines about their web pages in order to have their sites indexed more comprehensively and efficiently. A Sitemap is a file that resides on a server in conjunction with a web page (or large set of web pages) and acts as a marker for search engines to crawl certain pages. It's a convenient mechanism for webmasters to list all of their URLs along with optional metadata, such as the last time the page changed or when the page expires, to improve how search engines crawl their web sites.
Sitemaps enhance the current model of ‘‘discovery’’ crawling, where URLs are discovered by following links on a page. For example, Sitemaps address network bandwidth inefficiencies by offering hints to crawlers to not re-crawl unchanged pages. Sitemaps also help increase crawl comprehensiveness. For instance, letting a search engine find dynamic pages that aren't linked to other pages or are linked to pages contained in JavaScript, which can act as an inadvertent cloak. Sitemaps can also help provide faster page discovery. Another way to understand Sitemaps is to think of them as hints put forth by webmasters to help search engines increase the performance of current crawl methods. This in turn, helps webmasters get their sites indexed by search engines more comprehensively and efficiently and, ultimately, provides users with fresher search results.
The Google “Sitemaps” proposal is seriously being considered for endorsement by the major search vendors (IBM, Microsoft and Yahoo) and if universally adopted will greatly enhance and standardize the process of crawling for all search vendors. But what will be interesting to observe is if the webmasters themselves embrace the proposal. Currently the burden is entirely on the crawlers to discover what is available for indexing. No action is required by the webmasters except to make their content available on the web. In one sense, Google is asking these webmasters to take on additional work (to build and maintain a sitemap) in order to ease Google’s problems with crawling (a bit selfish it seems).
But many webmasters understand the value in being visible through a search engine. They also understand that you have to be in the game (index) in order to win. So it is in the interest of the webmaster too if the overall crawling process can be improved. With sitemaps webmasters would now have a more proactive route to take rather than a passive one with the current crawling model.
posted by Todd Leyba at 8:16 AM
![]()
![]()


0 Comments:
Post a Comment
<< Home