Text Analytics Summit 2006 Review
I just returned from attending the 2nd annual Text Analytics Summit held in Boston, June 22nd -23rd and thought I'd share with you my observations, views, and experiences at the conference. There were roughly 350 attendees, which is not bad for a new and emerging market. Text Analytics (TA) is experiencing a 35% growth rate and is the fourth fastest growing market in the IT industry as quoted by Susan Feldman from IDC.
In general I was impressed with the quality of the speakers and the technical content of the
 conference. I was hoping to be wowed with some of the latest analytics being applied to text but repeatedly saw the same named/entity extractors, categorizers, sentiment analyzers, etc. demonstrated by the various vendors. The demos seemed to blur into one, generally showing a target set of documents on the right with the various categorizations and extracted facts on the left. It seemed that most knew how to identify names, phone numbers, dates and the like but I couldn’t help but feel that the TA industry should be beyond this phase.
conference. I was hoping to be wowed with some of the latest analytics being applied to text but repeatedly saw the same named/entity extractors, categorizers, sentiment analyzers, etc. demonstrated by the various vendors. The demos seemed to blur into one, generally showing a target set of documents on the right with the various categorizations and extracted facts on the left. It seemed that most knew how to identify names, phone numbers, dates and the like but I couldn’t help but feel that the TA industry should be beyond this phase.Actually the relatively low “wow” factor may be indicative of the text analytics market as a whole. The vendors held a technology panel whose general consensus was that out-of-the-box text analytics is not here yet and has a considerable way to go. In order for text analytics to be effective it is necessary to take into account the context or domain of the problem space. This helps remove ambiguity and improve the overall accuracy of the analytic. For example, when encountering the phrase “drug trial” in a biomedical context you know that you are referring to the results of drug tests on human beings. But if you change the context to law enforcement then the same phrase refers to a criminal trial of drug dealers. This may explain why analysis of text without context can only be reduced to extracting simple entities and facts (names, dates, etc.).
But that’s not to say that customers could not take advantage of the technology today. There were many testimonials by customers describing how they have successfully deployed text analytic solutions for a variety of applications – competitive analysis, early warning detection, product image analysis, to name a few. But all of these took time (and money) to implement. They would start with the basic analytics provided out of the box, but then go through an iterative process of constant tweaking and fine tuning until they were satisfied with the results. The competitive advantage belonged to those vendors that had the tooling to facilitate this kind customization and refining. In my mind, Clearforest was one such vendor that appeared to have the most robust set of tooling.
UIMA and Text Analytics
Many customers expressed fears of being locked into a specific vendor given the amount of customization required to deploy the solution. They rightfully recognized that the greater the customization, which seems to be the case for most TA solutions, the further the deadly embrace with the vendor. IBM gave a session on the Unstructured Information Management Architecture (UIMA) which is a standard that enables customers to plug and play with an ala-carte of analytic modules. Each module can be dedicated to a specific type of analytic and provided by different vendors so long as the analytic conforms to the UIMA standard. UIMA was proposed by IBM over a year ago and most of the vendors were aware of its benefits to both them and their customers. During the technology panel the vendors were asked “How many of you have adopted or have near term plans to adopt UIMA”? Their answer – nearly all have adopted UIMA and the few that haven’t plan to within the year. Strike one up for the customer!OmniFind, IBM’s enterprise search engine, not surprisingly employs UIMA, and is one example of a search engine that can be extended with analytics provided by other vendors. One such case study was presented by NStein Technologies who extended OmniFind with their own UIMA compliant text analytic modules to provide a custom solution for their customer.
Search vs. Discovery (IDKWILFBIKIWISI)
There were two major applications for TA that seemed to emerge from the conference – that is text analytics used to augment search; and text analytics used for discovery. For search, text analytics enable you to go beyond providing just simple keywords and express yourself in more natural ways. It allows the search engine to understand the meaning behind your query and correctly match that with the meaning conveyed by the documents. With TA you can now ask questions like “Who is the current president of the United States" and not have documents returned containing the phrase “The United States invited president Putin to attend". Note that with TA the search engine might even be able to correctly answer the question with documents that only have the phrase “As Commander-In-Chief, George Bush addressed the troops”. Here a domain ontology would reflect the fact that the president of the United States is also the Commander-In-Chief and allow the search engine to make the connection (there’s that needed context again).Search is a very goal driven process because it is based on the premise that you already know what you are looking for. On the other hand there is a wealth of information locked inside the text that could be extremely relevant to your business but just hasn’t been discovered yet. Discovery is best characterized by the phrase “I Don’t Know What I’m Looking For, But I’ll Know It When I See It” (IDKWILFBIKIWISI). In this way text analytics complements Business Intelligence (BI) and data mining. Actually the conference was titled the “Text Mining Summit” last year and changed its name to address its broader applicability.
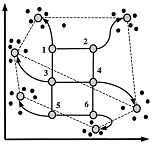
Discovery typically employs statistical approaches to analyze text. For example, clustering was one type of analytic prevalent at the conference that reveals clumps of documents with similar concentration of words and concepts and then graphically displays the results in a Self Organizing Map (SOM). With these maps one can visually scan extremely large sets of documents and quickly see the “clustering” of documents around a particular topic. For example, an automotive manufacture might notice that a large number of web documents are clustering around a specific brand of their vehicle prompting further investigation.
But more interestingly were the linguistic vendors that traditionally focused on fact extraction through natural language parsing moving towards discovery. Attensity was one such vendor that gave an excellent presentation titled “Is the Elephant Still in the Corner?”. Attensity’s contention was that goal based searching required a Subject Matter Expert (SME) and a Linguist working together to map the grammatical patterns and elements detected in text to columnar data elements of a relational database. Note that the transformation of textual data into relational data was a common movement by several vendors which I’ll comment on in a moment. But in either case, the mapping process with human intervention was the elephant which Attensity claimed no one was willing to acknowledge. The elephant is big, costly and time consuming.
Attensity’s new approach was to bypass the human factor altogether and have the text analytics exhaustively capture as many entity/relationships as possible and then store that information in just a few relational tables - basically an entity and relationship table. They then went on to demonstrate how using readily available BI tools they were able to query these tables to discover some amazing facts. In this particular case the data revealed that a weak weld joint was responsible for a failure in a mounting bracket in a car. I was a bit skeptical that just two tables representing entities and their relationships could reveal so much and it probably does have its limitations beyond the carefully scripted demo I saw, but hey, it’s better than not knowing and the possible ramifications of inaction in this case.
As I mentioned earlier, a lot of vendors were using the RDBMS as their ultimate store for the extracted information. Their argument was that RDBMS’ have been highly optimized to handle millions of rows of data and that there is quite a bit of advanced tooling available to query and analyze that data. Their other point was that extracting a fact out of text is just one part of the problem and that, in their experience, customer’s typically want to join the text data with other data they have stored (in RDBMS’) to provide a more holistic view of the entity. Think of joining a persons name with their credit history for example. Clarabridge, in addition to Attensity are two example vendors that adopt this approach.
Performance, Performance, Performance
One interesting but little advertised side affect of Text Analytics is that it is very compute intensive and takes an inordinate amount of time to analyze the content. One vendor quoted that it could take as long as one second to natural language parse (diagram) a single sentence in a document. A session presented by Ramana Rao from Inxight was dedicated to their efforts to improve their software’s analytic performance by 100X within three years (a very noble effort). They were challenged and funded by the federal government, probably to aid in their defense intelligence work and the massive amounts of text involved.Not surprisingly, Ramana postulated that the goal will best be met by leveraging both scaled up hardware as well as employing radically new architectures for TA in the software. The majority of the presentation was focused on how performance measurements were being made to develop a baseline and he did not suggest any radical approaches to TA yet. But I did find his remarks on hardware advances most intriguing. In particular was his reference to using GRID technology as one way to solve the hardware problem.
Grid computing enables the virtualization of distributed computing and data resources to create a single system image, granting users and applications seamless access to vast IT capabilities. Just as an Internet user views a unified instance of content via the Web, a grid user essentially sees a single, large virtual computer. As the amount of text to process grows and the complexity of the analytics increases it seems to me that an organization would be forced to leverage compute power outside of its means – much the way the SETI project leveraged home computers on the internet to crunch that vast amounts of data it had. IBM has made great advances in its GRID technology. Integrating UIMA into the GRID could someday bring about the possibility of having text analytics available on demand as a service through the grid (much the way we purchase electricity from the power grid).
Semi-Structured Information
During a round-table discussion, one customer brought up an interesting problem that few had answers for. His company dealt primarily with semi-structured information – information that was contained in tables or lists as both text and alphanumeric data. His goal was to extract this information for analysis while maintaining its context. That is to say that this column refers to a product number or that this column is a customer complaint description and so on. Sounds like the usual Extract/Transfer/Load (ETL) problem with the emphasis on Extract. But he said that the problem is that the semi-structured information followed no predictable template or pattern. The table of information could show up in an email or web page with no commonality between table formats. It might not be a table at all but rather a list with or without headings.One suggestion was to apply some governance to the problem by employing a content management system that mandated the use of predefined data templates. But he quickly rejected this idea as he had little or no control of how the information was authored. I suspect his organization was highly autonomous both organizationally and geographically. Another suggestion was to use some of the tools offered by the vendors at the conference to build customized parsers for the data. Again, he felt that this was impractical and said that he probably would need to write at least a hundred or more parsers. We didn’t have much time to understand the problem any further but if you have any ideas or possible solutions I’d be interested in hearing them
Conference Grade (B)
Overall I thought that the conference was very informative and worth while to participate in the future. Don’t hesitate to contact me if you have any questions or would like to discuss a topic in more detail.
posted by Todd Leyba at 1:11 PM
![]()
![]()


1 Comments:
Shame on you Todd! IBM's own WebSphere ProfileStage is designed to solve the very problem the customer described. Given a wide variety of data formats/structures of essentially the same data, it determines the ideal target schema for ETL-based consolidation of the data (using DataStage) in a mostly automated process. I'm sure there are a million and 1 techniques it uses to do this, but the core of the idea is that it compares the data values in many different ways.
3:13 AM
Post a Comment
<< Home